
What that you must know
- Google has introduced Android Bench to measure how properly AI fashions carry out actual Android app improvement duties.
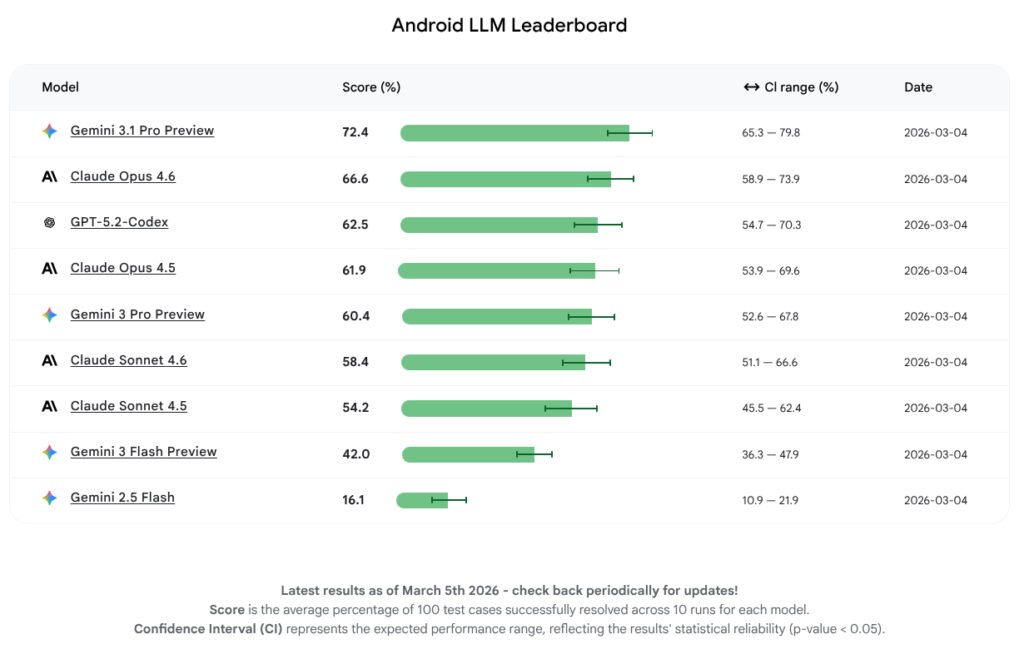
- Gemini 3.1 Professional tops the Android Bench leaderboard, outperforming Claude Opus and GPT Codex fashions.
- The benchmark assessments AI fashions utilizing actual Android coding challenges with various ranges of problem.
It is not nearly producing photos and movies from textual content anymore. Now you may even construct working apps utilizing only a immediate. That mentioned, not each AI mannequin that claims to construct apps performs equally properly, and Google desires to set a benchmark for which fashions truly work finest.
Vibe coding has shortly turn out to be one of many developments of 2026, with extra individuals making an attempt to construct their very own apps and companies utilizing AI. Nothing not too long ago showcased a instrument that lets customers create small apps utilizing prompts.
However anybody who has labored with Android improvement is aware of it takes extra than simply typing a couple of prompts, and Google desires to focus on which AI fashions are literally able to dealing with these duties.
To try this, Google has launched a brand new leaderboard referred to as Android Bench. It is a benchmark designed to judge massive language fashions particularly for Android improvement. The instrument measures how properly AI fashions carry out real-world Android improvement duties by testing them towards a set of challenges with various ranges of problem.

Based on Google, the examined fashions have been in a position to full between 16% and 72% of the duties efficiently. The mannequin that carried out finest was Google’s Gemini 3.1 Professional Preview with a rating of 72.2%. Claude Opus 4.6 adopted with a rating of 66.6%, whereas GPT 5.2 Codex completed third with 62.5%.
The outcomes present that AI fashions are already getting fairly succesful at serving to with Android improvement. Google says the purpose of Android Bench is to “shut the hole between idea and high quality code.” In the long term, the corporate believes individuals might construct Android apps just by describing what they need.
To make sure transparency, Google has additionally made the methodology, dataset, and testing instruments publicly accessible on GitHub.
Android Central’s Take
It might not matter a lot to the common person, however benchmarking LLMs particularly for Android improvement is nice for the developer group. It makes it simpler to establish which fashions are literally helpful for constructing apps as a substitute of counting on guesswork or making an attempt a number of instruments earlier than discovering one which works properly.