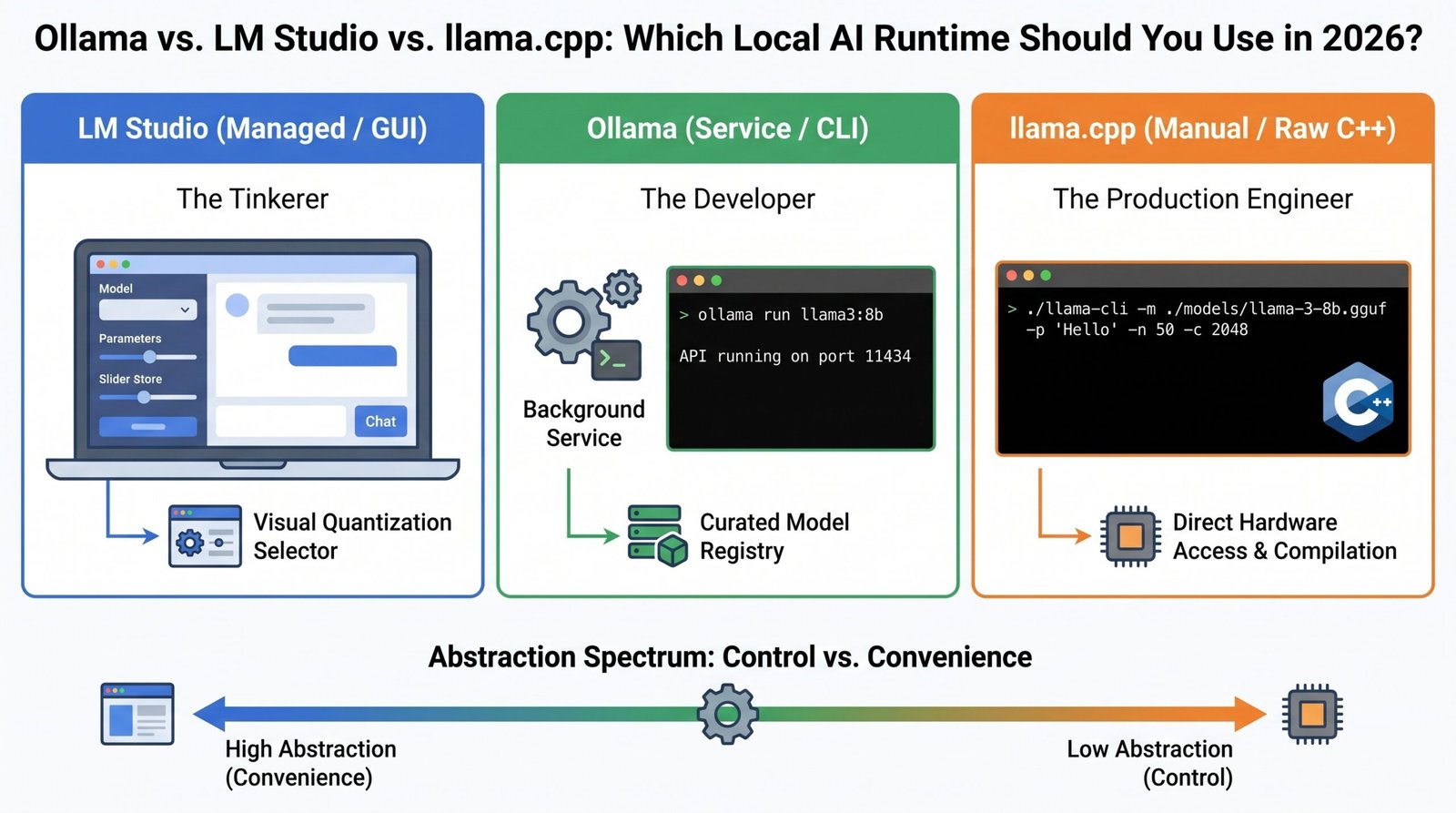
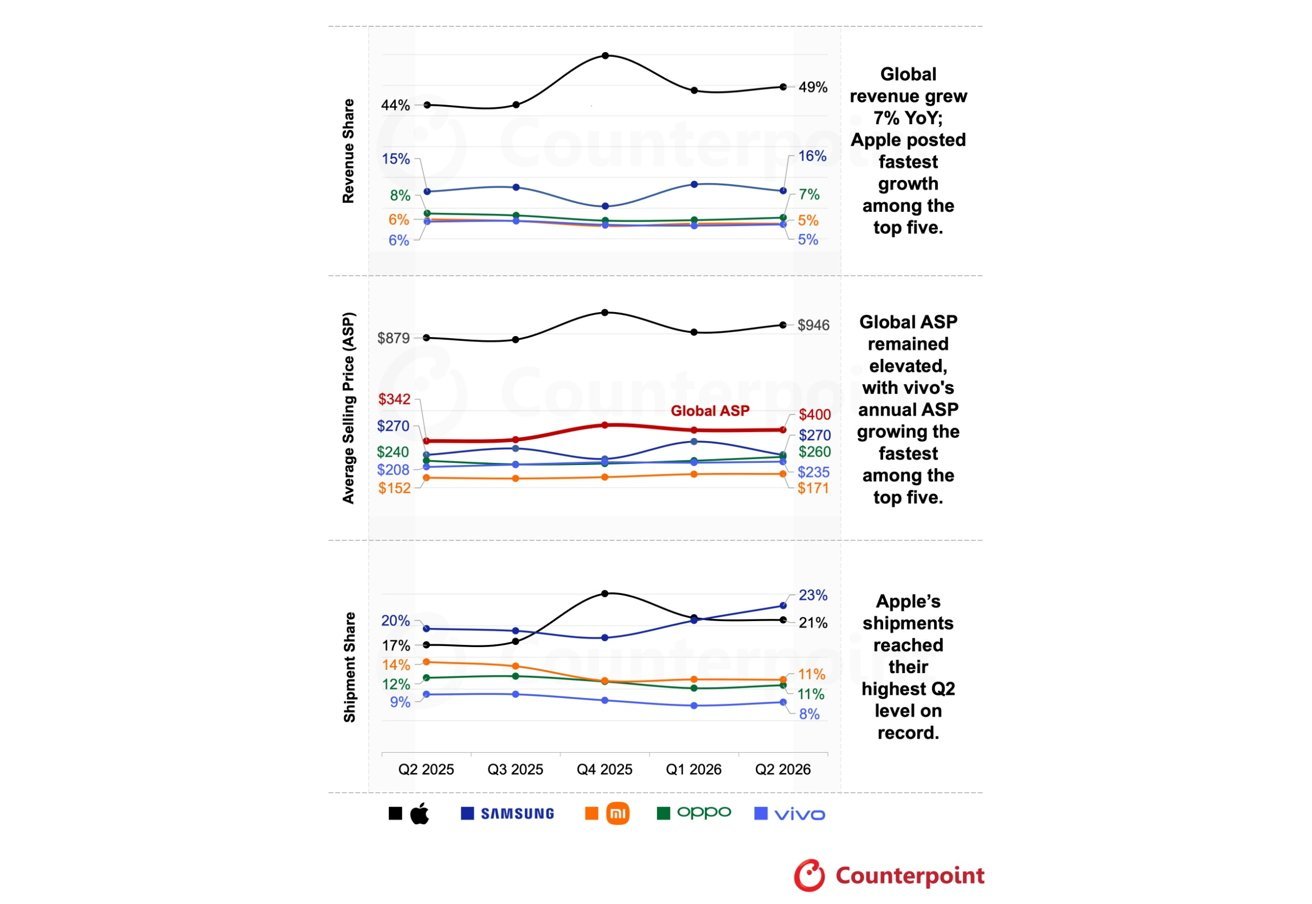
Anchoring within the African AI ecosystem
Essential to the WAXAL mission was our dedication to working with, and contributing on to, the African AI ecosystem. The information assortment effort was led completely by African tutorial and group organizations, guided by Google consultants on world-class knowledge assortment practices. This collaborative method ensured the corpus was constructed by and for the group it serves; with shared methodology every accomplice centered on a selected subset of languages. Our companions included Makerere College, which collected ASR and/or TTS knowledge for 9 totally different languages, and the College of Ghana, which centered its efforts on eight languages, utilizing the ASR image-prompted knowledge assortment methodology outlined above. Further key collaborators had been Digital Umuganda, in partnership with Addis Ababa College, who had been instrumental in main the ASR assortment for a number of regional languages. For the high-quality, studio-recorded voices, Media Belief, Loud n Clear and African Institute for Mathematical Sciences Senegal spearheaded the TTS recordings throughout varied regional languages.
This framework is basically rooted within the precept that our companions retain possession of the collected knowledge towards the shared dedication to make all datasets overtly out there for the broader group. This deep collaboration and open-access philosophy have already enabled notable spinoff analysis and publications.
- By this framework, our companions have already enabled new analysis, comparable to the event of a cookbook for community-driven assortment of impaired speech . This analysis resulted within the first open-source dataset for Akan audio system with circumstances like cerebral palsy and stammering, and demonstrated that in-person, image-prompted elicitation is simpler than text-based prompts for these populations. This work offers an important roadmap for growing inclusive speech applied sciences in low-resource environments.
- Moreover, the initiative supported a significant research that launched a 5,000-hour speech corpus for 5 Ghanaian languages — Akan, Ewe, Dagbani, Dagaare, and Ikposo. This work established infrastructure for constructing sturdy ASR and TTS methods tailor-made to the linguistic variety of West Africa through the use of a managed crowdsourcing method to seize pure, spontaneous intonations.
- Different important analysis has centered on benchmarking 4 state-of-the-art fashions (Whisper, XLS-R, MMS, and W2v-BERT) throughout 13 African languages. This research analyzed how efficiency scales with elevated coaching knowledge, providing key insights into knowledge effectivity and highlighting that scaling advantages are strongly depending on linguistic complexity and area alignment.
- Lastly, a scientific literature evaluate was printed, cataloging 74 datasets throughout 111 African languages to map the present frontier of speech expertise. This evaluate emphasised the pressing want for multi-domain conversational corpora and the adoption of linguistically knowledgeable metrics, comparable to Character Error Fee (CER), to higher consider efficiency in morphologically wealthy and tonal language contexts.