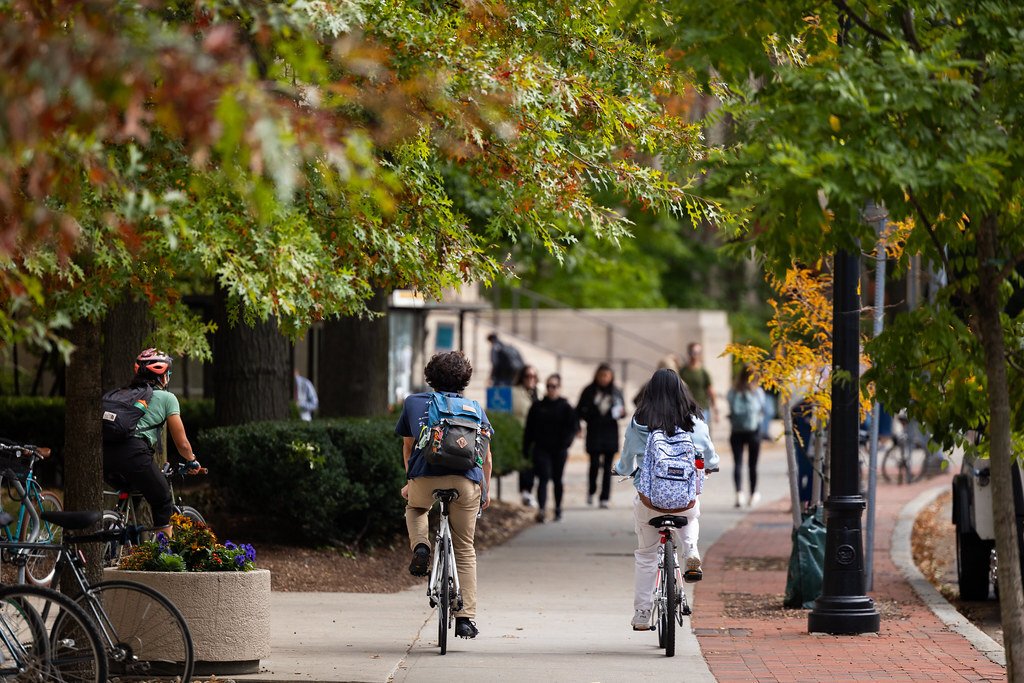Having highly effective Massive Language Fashions (LLMs) proper in your pocket is now a actuality with on-device fashions like Gemini Nano and Gemma. This expertise allows on a regular basis options in your telephone — similar to immediately summarizing a flurry of notifications or proofreading an necessary textual content message — all with out sending your non-public information off gadget. However to make these options helpful for on a regular basis customers, they should occur very effectively.
Delivering this sort of velocity on a cellular gadget is a big problem. In contrast to huge server environments, cell phones function below a strict vitality funds and laborious reminiscence (RAM) limits. Moreover, normal language fashions generate textual content “autoregressively” — which means they course of and output only one phrase (or token) at a time. This step-by-step course of creates a bottleneck, underutilizing the telephone’s processing energy whereas straining its reminiscence bandwidth, which may in the end decelerate the person expertise and drain the battery.
To beat this bottleneck, we’re saying a brand new structure that retrofits Multi-Token Prediction (MTP) onto current, “frozen” Gemini Nano v3 fashions. Constructing on prior approaches just like the EAGLE framework and Assured Adaptive Language Modeling (CALM), we designed new architectural elements to maximise these effectivity positive factors particularly for cellular environments. Our latest bulletins highlighted accelerating Gemma 4 with MTP and making it accessible to builders.
As we speak’s article tackles the distinctive, excessive constraints of edge computing. Just lately rolled out to the Pixel 9 and 10 collection, this strategy acts as an out-of-the-box speedup. For customers, which means options like AI Notification Summaries and Proofread generate textual content considerably sooner and with much less vitality consumption. For builders, it eliminates a serious friction level: delivering high-speed on-device AI with out the necessity to fine-tune separate, memory-heavy drafting fashions for each new activity.